9.3 什么是 DataFrame
与 RDD 类似,DataFrame 也是一个分布式数据容器。
然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。
同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。
从 API 易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的 RDD API 要更加友好,门槛更低。
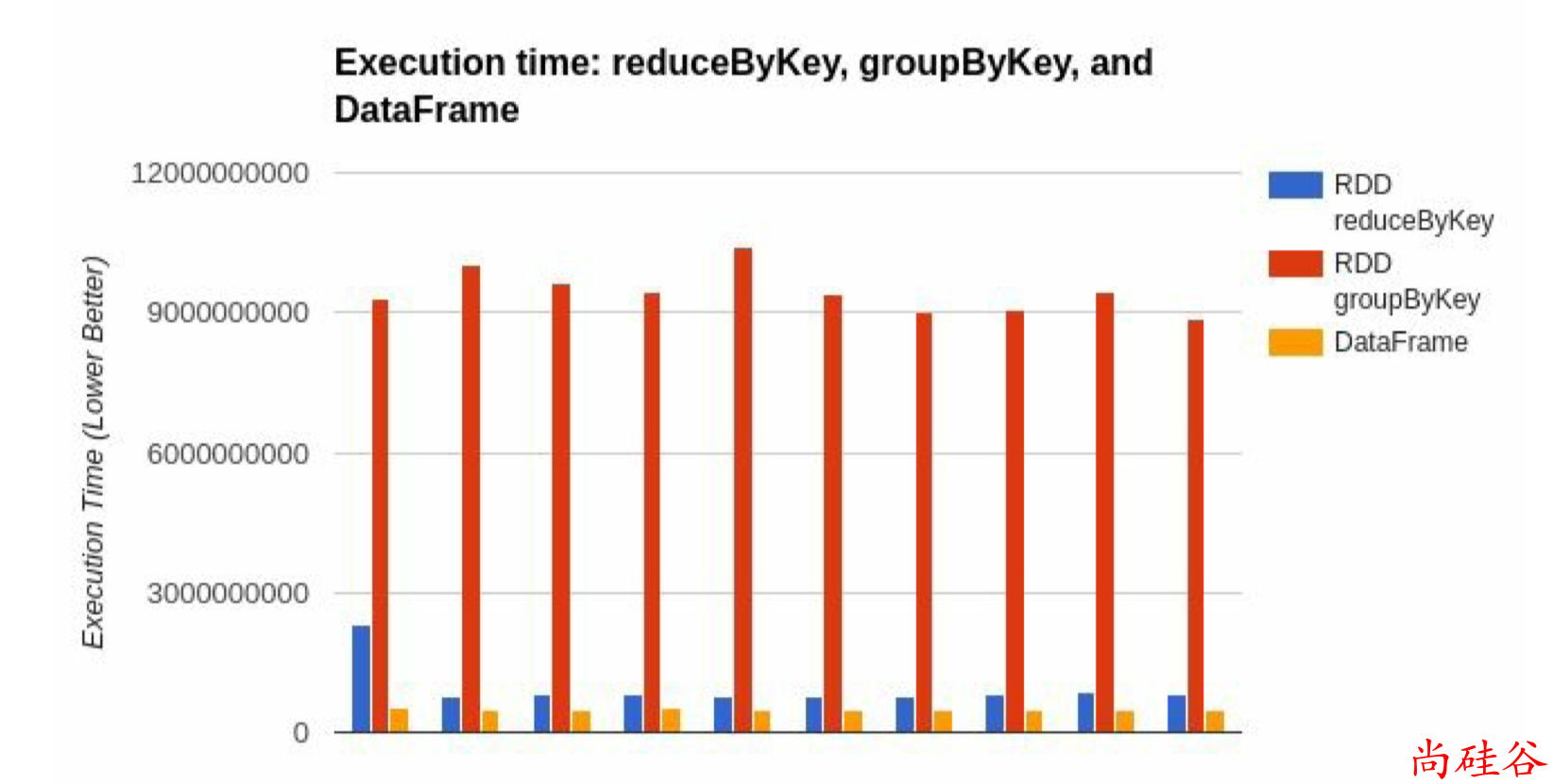
上图直观地体现了DataFrame和RDD的区别。
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。
而右侧的DataFrame却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待,
DataFrame也是懒执行的
性能上比 RDD要高,主要原因:
优化的执行计划:查询计划通过Spark catalyst optimiser进行优化。比如下面一个例子:
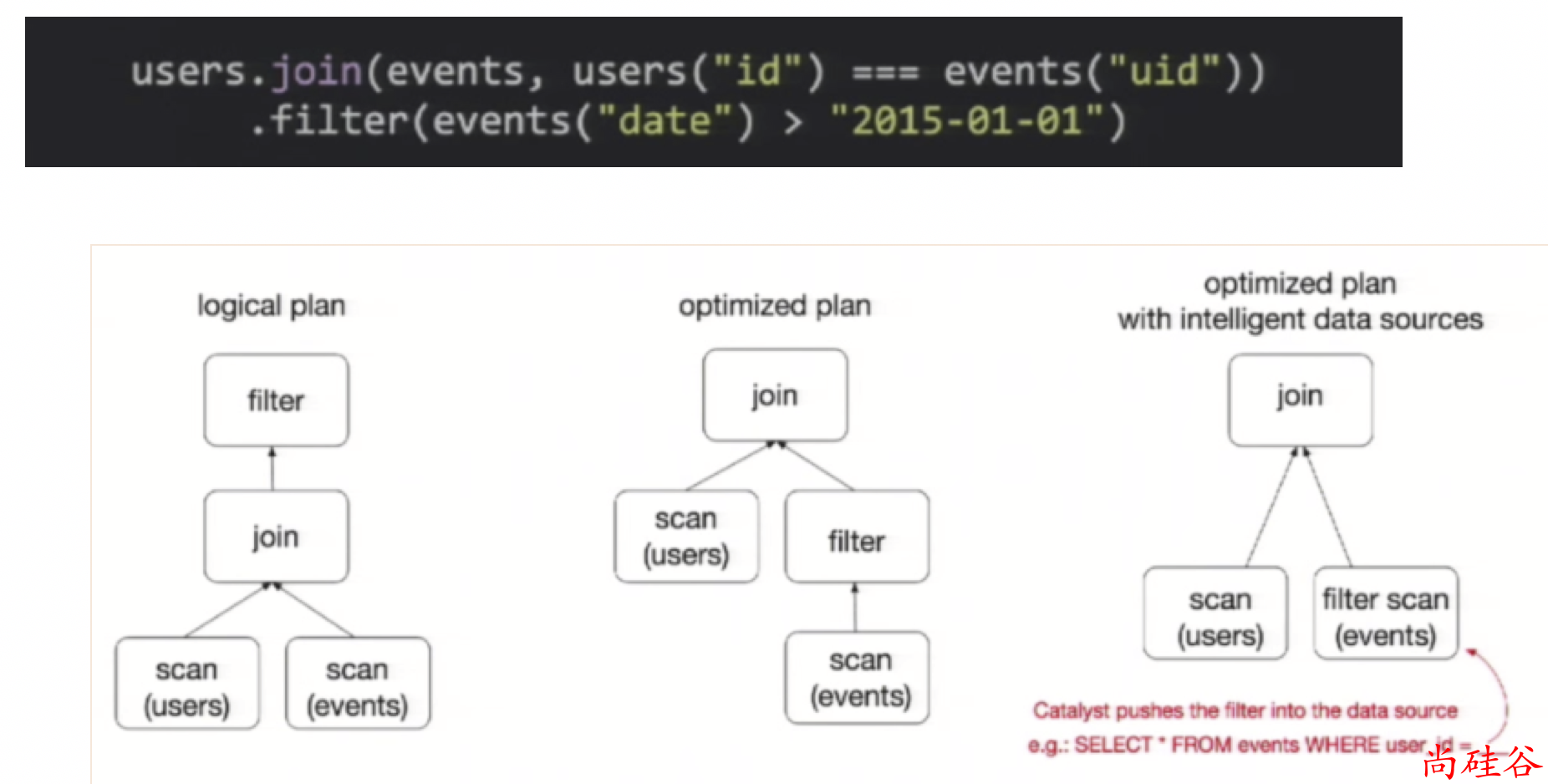
为了说明查询优化,我们来看上图展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。
如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。
如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。
而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。