2.2 Spark 核心概念介绍
driver program(驱动程序)
每个 Spark 应用程序都包含一个驱动程序, 驱动程序负责把并行操作发布到集群上.
驱动程序包含 Spark 应用程序中的主函数, 定义了分布式数据集以应用在集群中.
在前面的wordcount案例集中, spark-shell 就是我们的驱动程序, 所以我们可以在其中键入我们任何想要的操作, 然后由他负责发布.
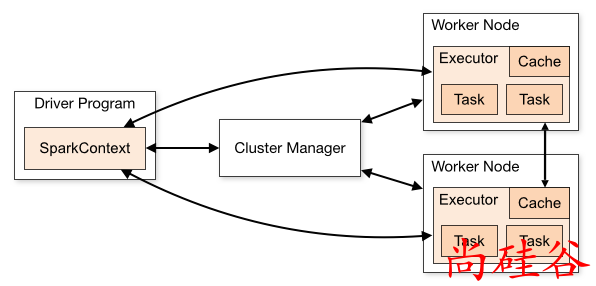
驱动程序通过SparkContext对象来访问 Spark, SparkContext对象相当于一个到 Spark 集群的连接.
在 spark-shell 中, 会自动创建一个SparkContext对象, 并把这个对象命名为sc.
RDDs(Resilient Distributed Dataset) 弹性分布式数据集
一旦拥有了SparkContext对象, 就可以使用它来创建 RDD 了. 在前面的例子中, 我们调用sc.textFile(...)来创建了一个 RDD, 表示文件中的每一行文本. 我们可以对这些文本行运行各种各样的操作.
在第二部分的SparkCore中, 我们重点就是学习 RDD.
cluster managers(集群管理器)
为了在一个 Spark 集群上运行计算, SparkContext对象可以连接到几种集群管理器(Spark’s own standalone cluster manager, Mesos or YARN).
集群管理器负责跨应用程序分配资源.
executor(执行器)
SparkContext对象一旦成功连接到集群管理器, 就可以获取到集群中每个节点上的执行器(executor).
执行器是一个进程(进程名: ExecutorBackend, 运行在 Worker 上), 用来
然后, Spark 会发送应用程序代码(比如:jar包)到每个执行器. 最后, SparkContext对象发送任务到执行器开始执行程序.
专业术语
| Term | Meaning |
|---|---|
| Application | User program built on Spark. Consists of a driver program and executors on the cluster. (构建于 Spark 之上的应用程序. 包含驱动程序和运行在集群上的执行器) |
| Application jar | A jar containing the user's Spark application. In some cases users will want to create an "uber jar" containing their application along with its dependencies. The user's jar should never include Hadoop or Spark libraries, however, these will be added at runtime. |
| Driver program | The process running the main() function of the application and creating the SparkContext |
| Cluster manager | An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) |
| Deploy mode | Distinguishes where the driver process runs. In "cluster" mode, the framework launches the driver inside of the cluster. In "client" mode, the submitter launches the driver outside of the cluster. |
| Worker node | Any node that can run application code in the cluster |
| Executor | A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. |
| Task | A unit of work that will be sent to one executor |
| Job | A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you'll see this term used in the driver's logs. |
| Stage | Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you'll see this term used in the driver's logs. |