5.10 设置检查点
Spark 中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过 Lineage 做容错的辅助
Lineage 过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的 RDD 开始重做 Lineage,就会减少开销。
检查点通过将数据写入到 HDFS 文件系统实现了 RDD 的检查点功能。
为当前 RDD 设置检查点。该函数将会创建一个二进制的文件,并存储到 checkpoint 目录中,该目录是用 SparkContext.setCheckpointDir()设置的。在 checkpoint 的过程中,该RDD 的所有依赖于父 RDD中 的信息将全部被移除。
package day04
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CheckPointDemo {
def main(args: Array[String]): Unit = {
// 要在SparkContext初始化之前设置, 都在无效
System.setProperty("HADOOP_USER_NAME", "atguigu")
val conf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sc = new SparkContext(conf)
// 设置 checkpoint的目录. 如果spark运行在集群上, 则必须是 hdfs 目录
sc.setCheckpointDir("hdfs://hadoop201:9000/checkpoint")
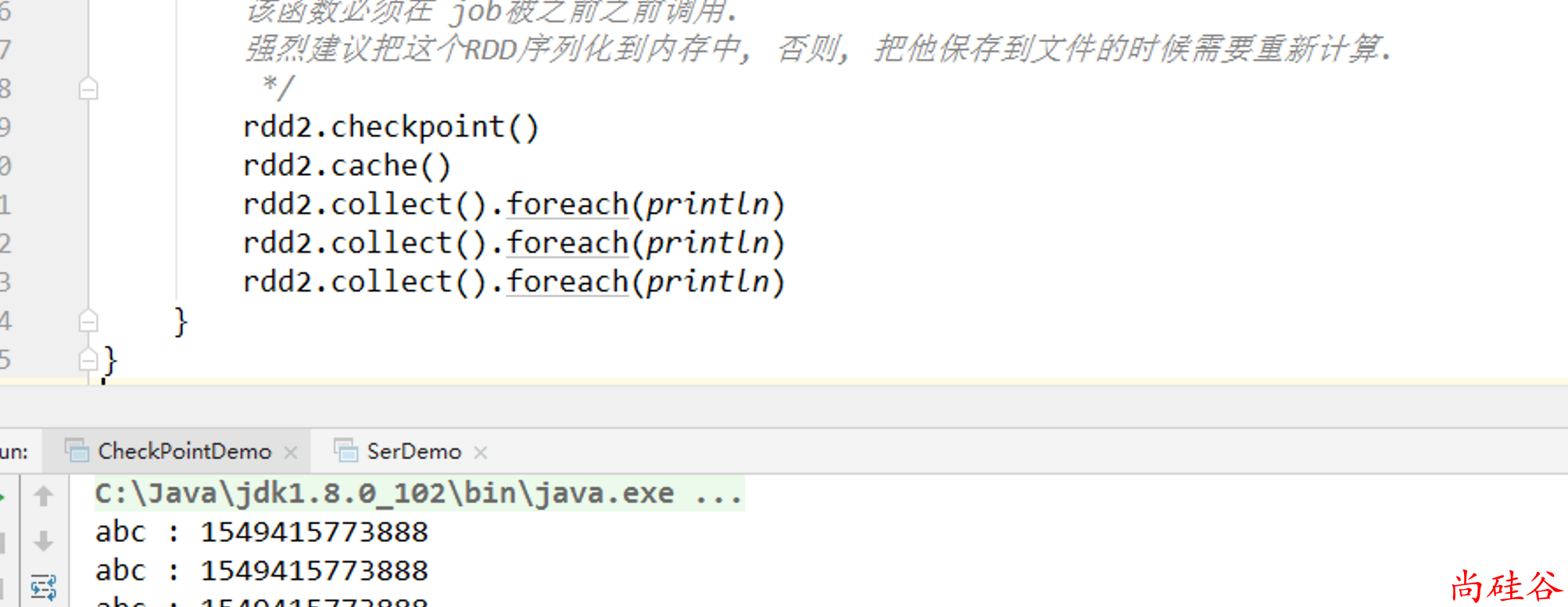
val rdd1 = sc.parallelize(Array("abc"))
val rdd2: RDD[String] = rdd1.map(_ + " : " + System.currentTimeMillis())
/*
标记 RDD2的 checkpoint.
RDD2会被保存到文件中(文件位于前面设置的目录中), 并且会切断到父RDD的引用, 也就是切断了它向上的血缘关系
该函数必须在job被执行之前调用.
强烈建议把这个RDD序列化到内存中, 否则, 把他保存到文件的时候需要重新计算.
*/
rdd2.checkpoint()
rdd2.collect().foreach(println)
rdd2.collect().foreach(println)
rdd2.collect().foreach(println)
}
}

持久化和checkpoint的区别
持久化只是将数据保存在 BlockManager 中,而 RDD 的 Lineage 是不变的。但是
checkpoint执行完后,RDD 已经没有之前所谓的依赖 RDD 了,而只有一个强行为其设置的checkpointRDD,RDD 的 Lineage 改变了。持久化的数据丢失可能性更大,磁盘、内存都可能会存在数据丢失的情况。但是
checkpoint的数据通常是存储在如 HDFS 等容错、高可用的文件系统,数据丢失可能性较小。注意: 默认情况下,如果某个 RDD 没有持久化,但是设置了
checkpoint,会存在问题. 本来这个 job 都执行结束了,但是由于中间 RDD 没有持久化,checkpoint job 想要将 RDD 的数据写入外部文件系统的话,需要全部重新计算一次,再将计算出来的 RDD 数据 checkpoint到外部文件系统。 所以,建议对checkpoint()的 RDD 使用持久化, 这样 RDD 只需要计算一次就可以了.