1.3 Spark 内置模块介绍
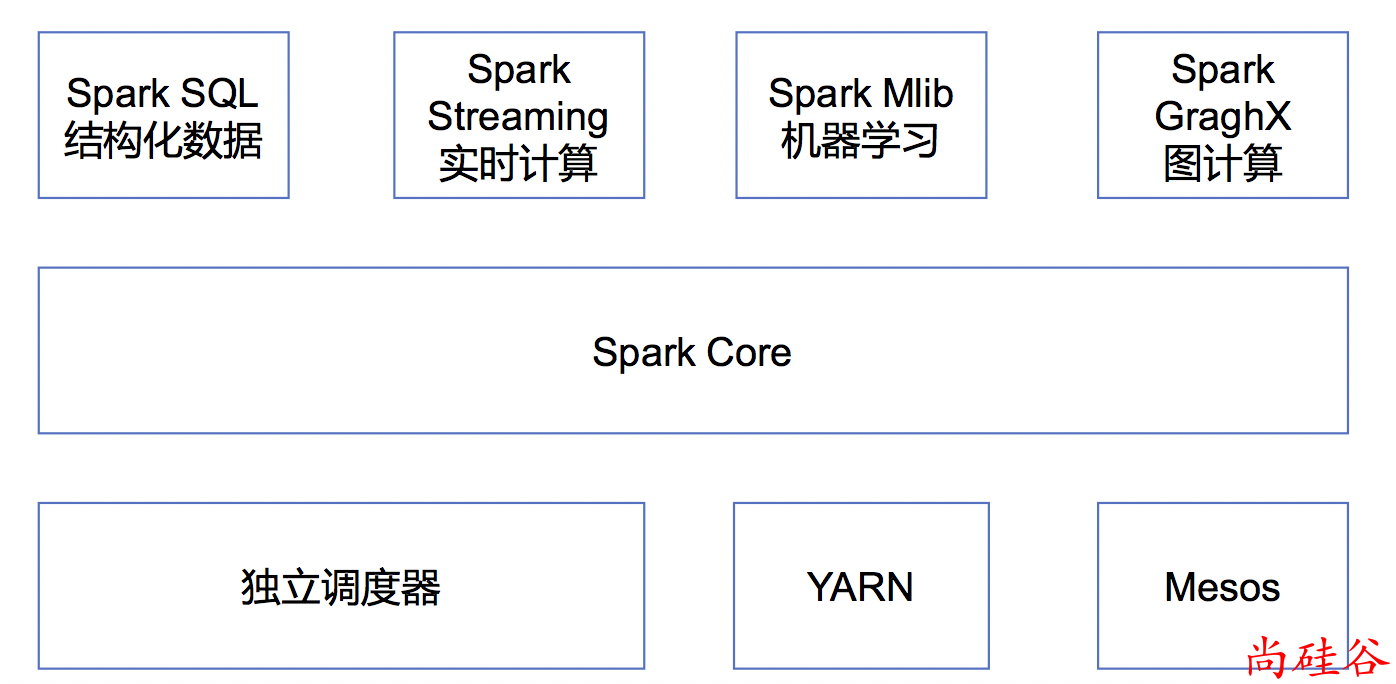
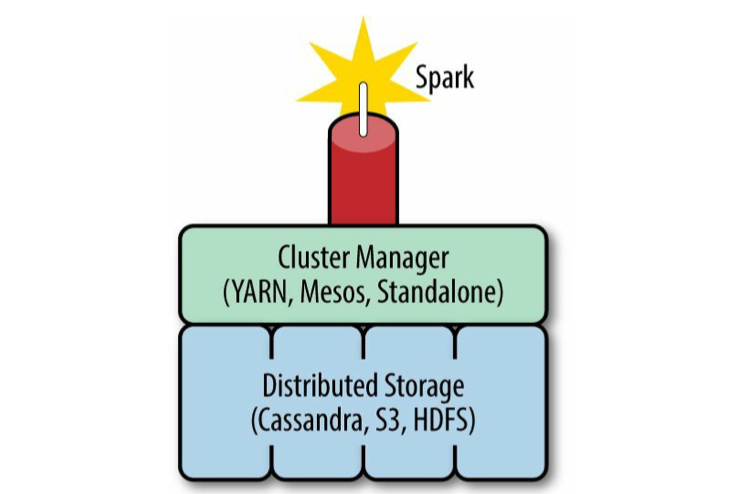
集群管理器(Cluster Manager)
Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(Cluster Manager)上运行,目前 Spark 支持 3 种集群管理器:
Hadoop YARN(在国内使用最广泛) Apache Mesos(国内使用较少, 国外使用较多)
Standalone(Spark 自带的资源调度器, 需要在集群中的每台节点上配置 Spark)
SparkCore
实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。SparkCore 中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL
是 Spark 用来操作结构化数据的程序包。通过SparkSql,我们可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming
是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib
提供常见的机器学习 (ML) 功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
Spark 得到了众多大数据公司的支持,这些公司包括 Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。
当前百度的 Spark 已应用于大搜索、直达号、百度大数据等业务;
阿里利用 GraphX 构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;