5.3.1 Value 类型---1
1. map(func)
作用: 返回一个新的 RDD, 该 RDD 是由原 RDD 的每个元素经过函数转换后的值而组成. 就是对 RDD 中的数据做转换.
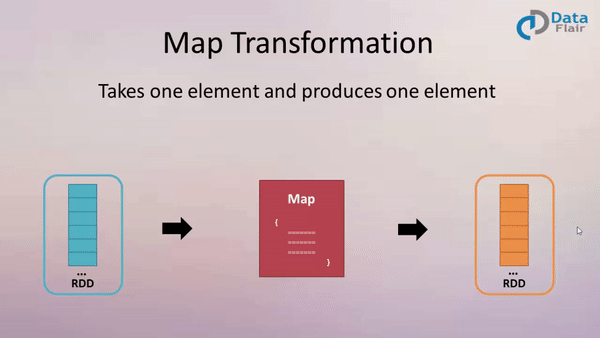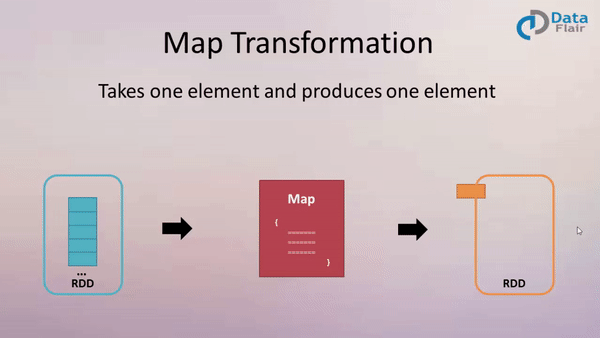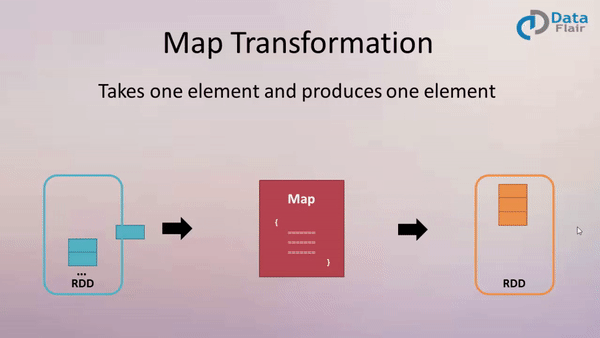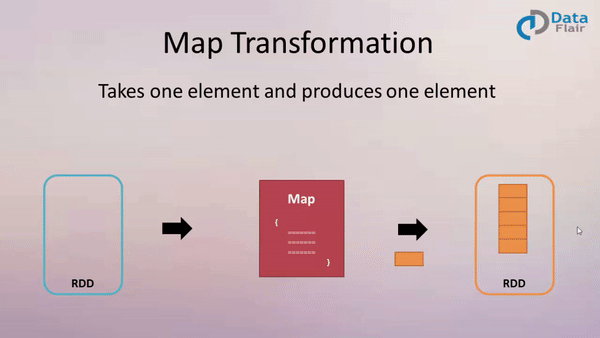
案例:
创建一个包含1-10的的 RDD,然后将每个元素*2形成新的 RDD
scala > val rdd1 = sc.parallelize(1 to 10)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
// 得到一个新的 RDD, 但是这个 RDD 中的元素并不是立即计算出来的
scala> val rdd2 = rdd1.map(_ * 2)
rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at
<console>:26
// 开始计算 rdd2 中的元素, 并把计算后的结果传递给驱动程序
scala> rdd2.collect
res0: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
3. mapPartitionsWithIndex(func)
作用: 和mapPartitions(func)类似. 但是会给func多提供一个Int值来表示分区的索引. 所以func的类型是:(Int, Iterator<T>) => Iterator<U>
scala> val rdd1 = sc.parallelize(Array(10,20,30,40,50,60))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd1.mapPartitionsWithIndex((index, items) => items.map((index, _)))
res8: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[3] at mapPartitionsWithIndex at <console>:27
scala> res8.collect
res9: Array[(Int, Int)] = Array((0,10), (0,20), (0,30), (1,40), (1,50), (1,60))
分区数的确定, 和对数组中的元素如何进行分区
确定分区数:
override def defaultParallelism(): Int = scheduler.conf.getInt("spark.default.parallelism", totalCores)对元素进行分区
// length: RDD 中数据的长度 numSlices: 分区数 def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { (0 until numSlices).iterator.map { i => val start = ((i * length) / numSlices).toInt val end = (((i + 1) * length) / numSlices).toInt (start, end) } } seq match { case r: Range => case nr: NumericRange[_] => case _ => val array = seq.toArray // To prevent O(n^2) operations for List etc positions(array.length, numSlices).map { case (start, end) => array.slice(start, end).toSeq }.toSeq }
4. flatMap(func)
作用: 类似于map,但是每一个输入元素可以被映射为 0 或多个输出元素(所以func应该返回一个序列,而不是单一元素 T => TraversableOnce[U])
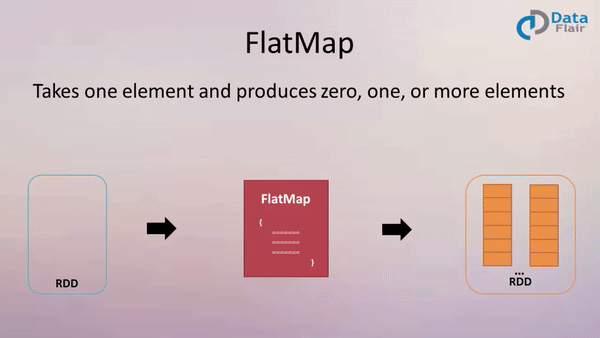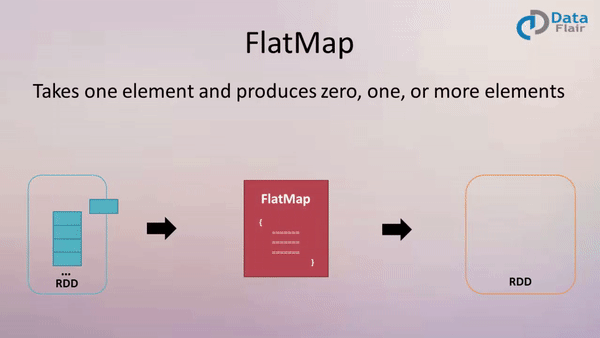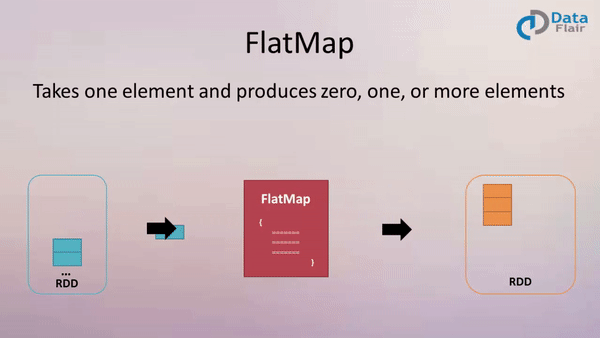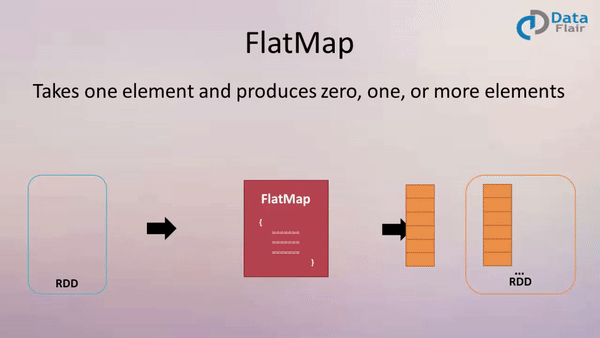
案例:
创建一个元素为 1-5 的RDD,运用 flatMap创建一个新的 RDD,新的 RDD 为原 RDD
每个元素的 平方和三次方 来组成 1,1,4,8,9,27..
scala> val rdd1 = sc.parallelize(Array(1,2,3,4,5))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at parallelize at <console>:24
scala> rdd1.flatMap(x => Array(x * x, x * x * x))
res13: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at flatMap at <console>:27
scala> res13.collect
res14: Array[Int] = Array(1, 1, 4, 8, 9, 27, 16, 64, 25, 125)
5. map()和mapPartition()的区别
map():每次处理一条数据。mapPartition():每次处理一个分区的数据,这个分区的数据处理完后,原 RDD 中该分区的数据才能释放,可能导致 OOM。开发指导:当内存空间较大的时候建议使用
mapPartition(),以提高处理效率。
6. glom()
作用: 将每一个分区的元素合并成一个数组,形成新的 RDD 类型是RDD[Array[T]]
案例
创建一个 4 个分区的 RDD,并将每个分区的数据放到一个数组
scala> var rdd1 = sc.parallelize(Array(10,20,30,40,50,60), 4)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd1.glom.collect
res2: Array[Array[Int]] = Array(Array(10), Array(20, 30), Array(40), Array(50, 60))
7. groupBy(func)
作用:
按照func的返回值进行分组.
func返回值作为 key, 对应的值放入一个迭代器中. 返回的 RDD: RDD[(K, Iterable[T])
每组内元素的顺序不能保证, 并且甚至每次调用得到的顺序也有可能不同.
案例:
创建一个 RDD,按照元素的奇偶性进行分组
scala> val rdd1 = sc.makeRDD(Array(1, 3, 4, 20, 4, 5, 8))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at makeRDD at <console>:24
scala> rdd1.groupBy(x => if(x % 2 == 1) "odd" else "even")
res4: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[4] at groupBy at <console>:27
scala> res4.collect
res5: Array[(String, Iterable[Int])] = Array((even,CompactBuffer(4, 20, 4, 8)), (odd,CompactBuffer(1, 3, 5)))
8. filter(func)
作用: 过滤. 返回一个新的 RDD 是由func的返回值为true的那些元素组成
案例
创建一个 RDD(由字符串组成),过滤出一个新 RDD(包含"xiao"子串)
scala> val names = sc.parallelize(Array("xiaoli", "laoli", "laowang", "xiaocang", "xiaojing", "xiaokong"))
names: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> names.filter(_.contains("xiao"))
res3: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at filter at <console>:27
scala> res3.collect
res4: Array[String] = Array(xiaoli, xiaocang, xiaojing, xiaokong)
9. sample(withReplacement, fraction, seed)
作用:
以指定的随机种子随机抽样出比例为
fraction的数据,(抽取到的数量是:size * fraction). 需要注意的是得到的结果并不能保证准确的比例.withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样. 放回表示数据有可能会被重复抽取到,false则不可能重复抽取到. 如果是false, 则fraction必须是:[0,1], 是true则大于等于0就可以了.seed用于指定随机数生成器种子。 一般用默认的, 或者传入当前的时间戳
不放回抽样
scala> val rdd1 = sc.parallelize(1 to 10)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[15] at parallelize at <console>:24
scala> rdd1.sample(false, 0.5).collect
res15: Array[Int] = Array(1, 3, 4, 7)
放回抽样
scala> rdd1.sample(true, 2).collect
res25: Array[Int] = Array(1, 1, 2, 3, 3, 4, 4, 5, 5, 5, 5, 5, 6, 6, 7, 7, 8, 8, 9)
10. distinct([numTasks]))
作用:
对 RDD 中元素执行去重操作. 参数表示任务的数量.默认值和分区数保持一致.
scala> val rdd1 = sc.parallelize(Array(10,10,2,5,3,5,3,6,9,1))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:24
scala> rdd1.distinct().collect
res29: Array[Int] = Array(6, 10, 2, 1, 3, 9, 5)
2. mapPartitions(func)
作用: 类似于map(func), 但是是独立在每个分区上运行.所以:Iterator<T> => Iterator<U>
假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区。
scala> val source = sc.parallelize(1 to 10)
source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at parallelize at <console>:24
scala> source.mapPartitions(it => it.map(_ * 2))
res7: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at mapPartitions at <console>:27
scala> res7.collect
res8: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)