9.3.6 count(distinct)去重统计
数据量小的时候无所谓,数据量大的情况下,由于 COUNT DISTINCT 操作需要用一个Reduce Task来完.
如果这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换:
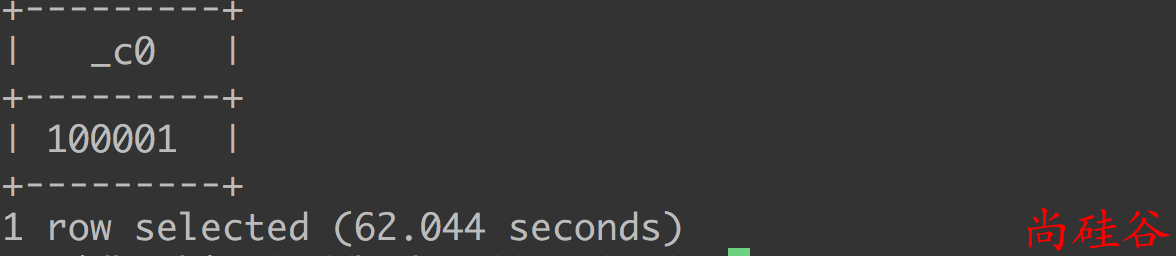
步骤1: 直接使用count(distinct) 进行去重复 id 的查询
set mapreduce.job.reduces = 5;
select count(distinct id) from bigtable;


步骤2: 采用 GROUP by去重 id
select count(id) from (select id from bigtable group by id) a;