5.1 数据导入
5.1.1 向表中装载文件
Hive 处理的数据多是以文件的方式存在的.
所以 Hive 最常见的就是把数据导入到数据库中.
语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
说明:
load data表示加载数据local表示从本地文件系统导入数据. 如果不加local表示从 HDFS 文件系统导入数据filepath用引号括起来, 表示要加载的数据的路径.overwrite表示覆盖表中已有数据, 不加参数表示追加数据到表中.partition上传到指定分区.
实例1: 从 HDFS 加载数据到表中
步骤1: 把文件加载到 HDFS: /dept.txt
hadoop fs -put /opt/module/datas/dept.txt /dept.txt
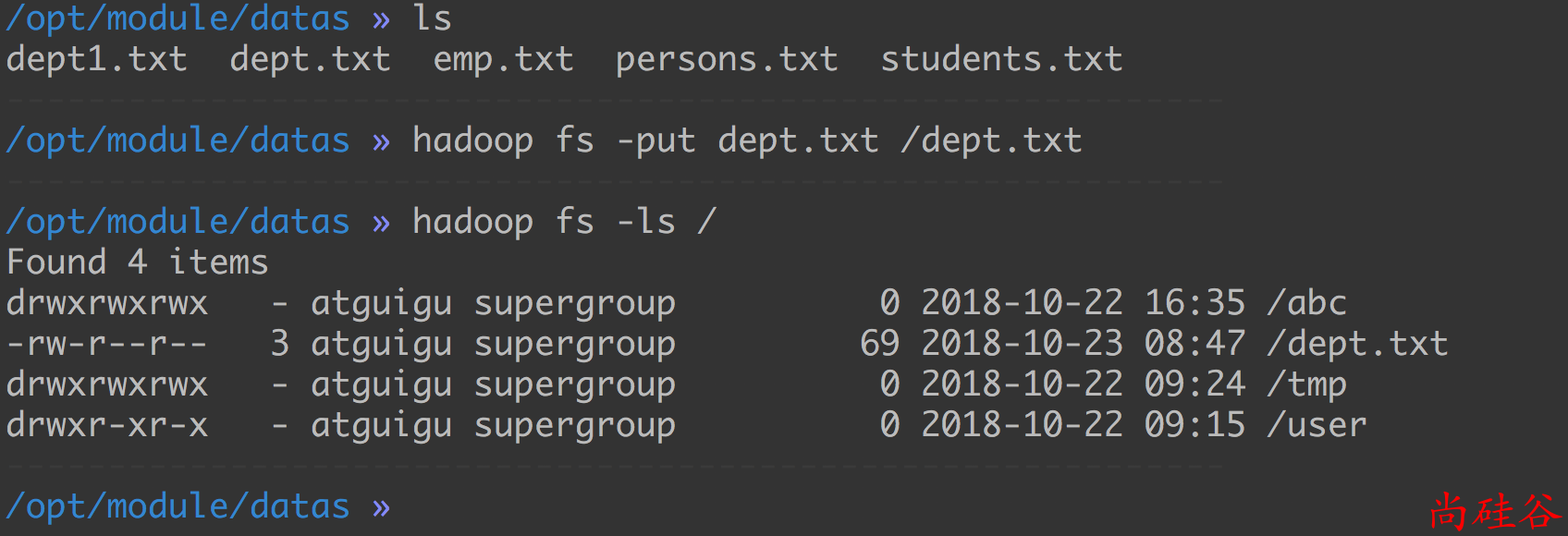
步骤2: 把 HDFS 上的文件/dept.txt加载到表dept中
不添加local 几句标号加载 HDFS 上的文件
load data inpath '/dept.txt' into table dept;
5.1.2 把查询结果插入到表中
步骤1: 创建一张分区表
create table student_1(id int, name string)
partitioned by(year string)
row format delimited
fields terminated by '\t';
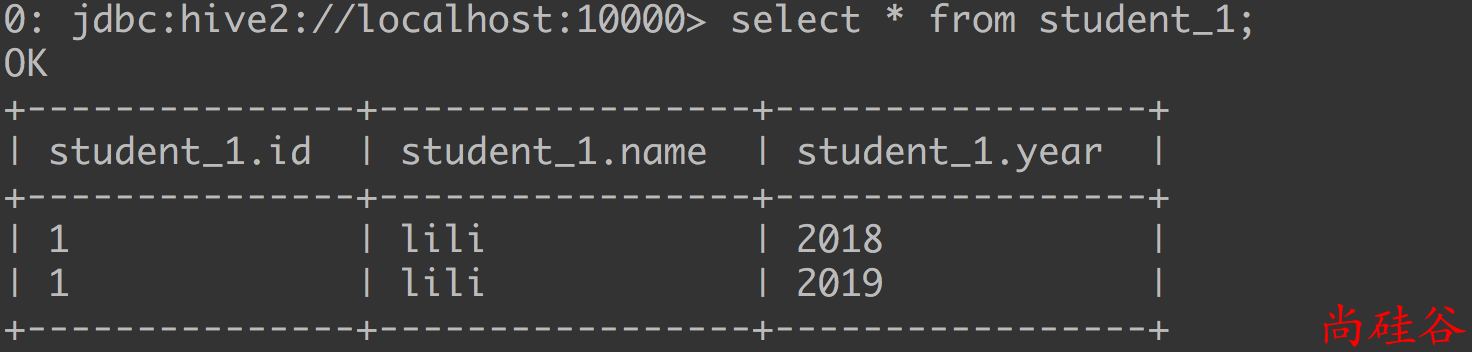
步骤2: 插入一条数据
insert into table student_1 partition(year='2018') values(1, "lili");
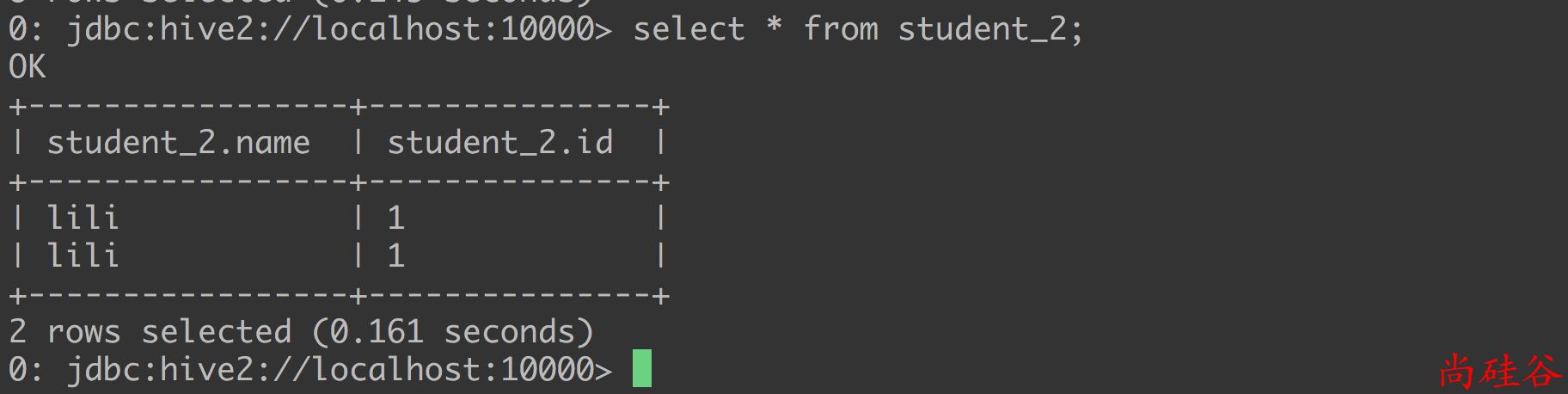
步骤3: 查询刚才的那条数据, 并插入到新的分区中
insert overwrite table student_1 partition(year='2019')
select id, name
from student_1
where year='2018';
步骤4: 查询结果
步骤5: 多插入模式
from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';
5.1.3 As Select
是指创建表的同时插入查询到的结果
create table if not exists student3
as select id, name from student;
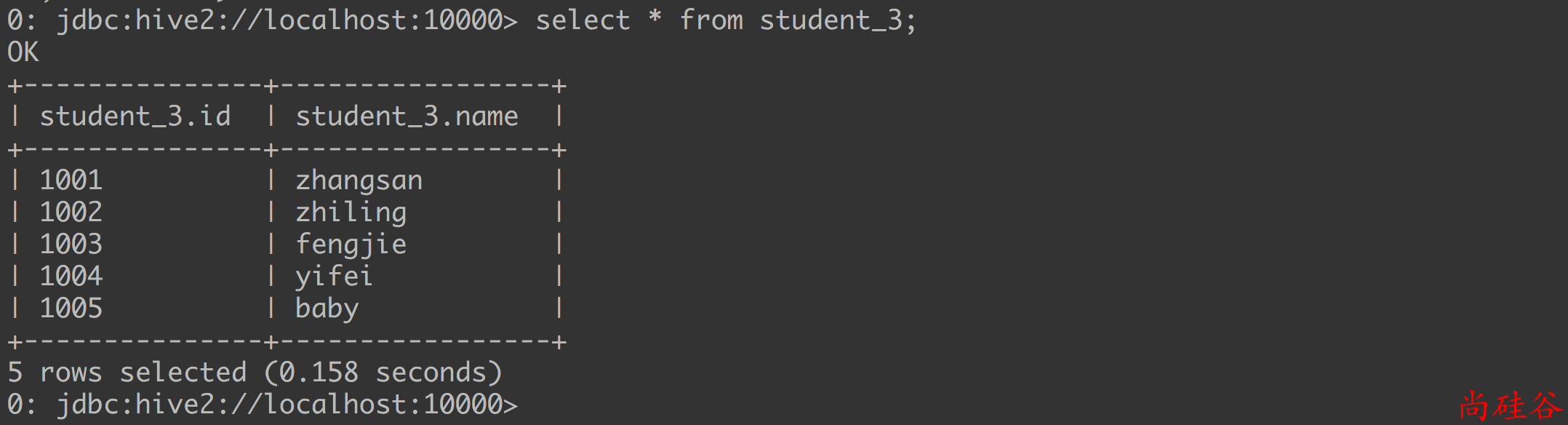
5.1.4 创建表时通过 location 指定数据路径
步骤1: 创建表, 并指定路径
create table if not exists student_3(
id int, name string
)
row format delimited fields terminated by '\t'
location '/user/hive/warehouse/student_3';
步骤2: 上传数据到 HDFS 上/user/hive/warehouse/student_3
hadoop fs -put /opt/module/datas/students.txt /user/hive/warehouse/student_3;
步骤3: 查询结果
select * from student_3;