9.3.3 空 key 转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,这个时候过滤掉 null 是不合理的.
此时我们可以表 a中 key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。例如:
步骤1: 为了可以方便的看到每个 Reduce 的执行情况, 我们开启 MapReduce 的历史服务器
配置 Hadoop 的 mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop202:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop202:19888</value>
</property>
开启历史服务区!
mr-jobhistory-daemon.sh start historyserver
步骤2: 不随机分布 null 的值
- 设置
reduce的个数是 5set mapreduce.job.reduces = 5; JOIN两张表insert overwrite table jointable select n.* from nullidtable n left join ori b on n.id = b.id;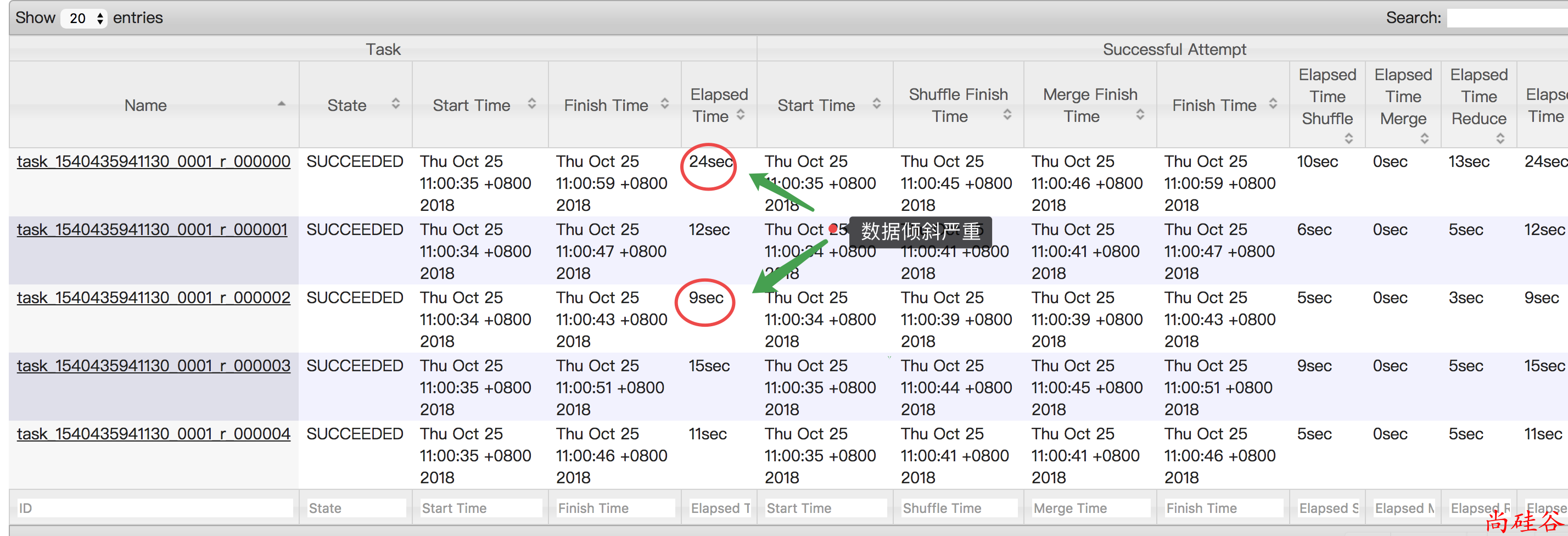
因为空 null 比较多, 他们会进同一个 reduce, 所以耗时比较长.
步骤2: 随机分布 null 的值
insert overwrite table jointable
select n.* from nullidtable n full join ori o
on (case when n.id is null then concat('hive', rand()) else n.id end) = o.id;
