第 5 章 Spark Shuffle 解析
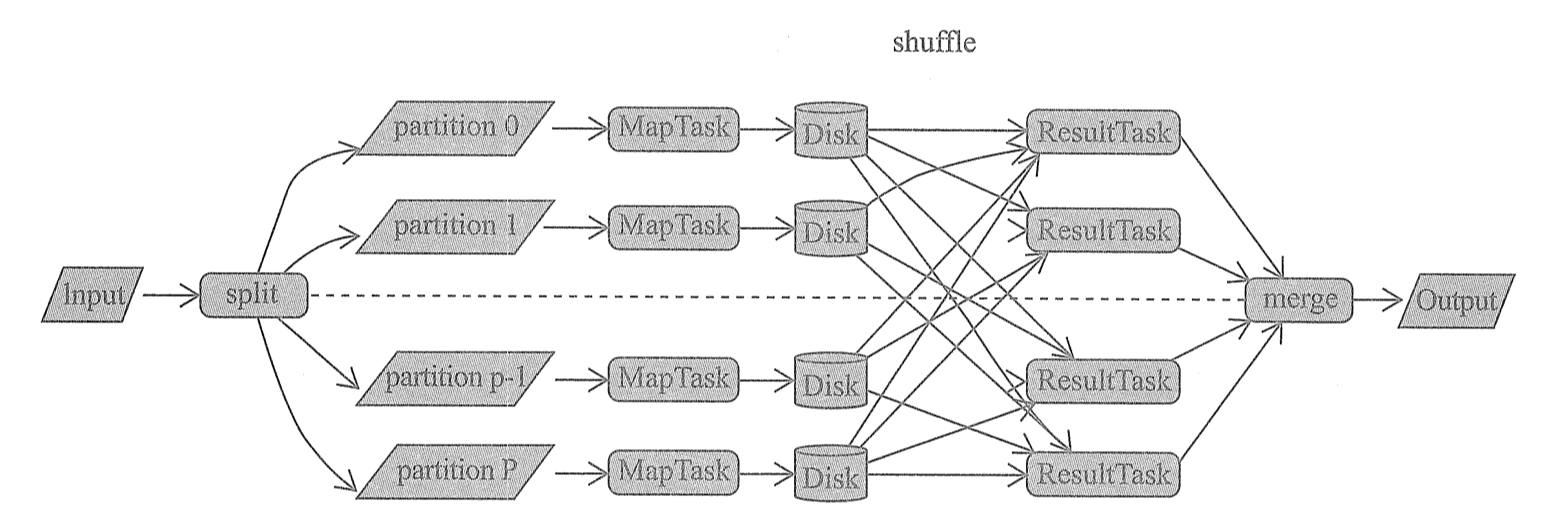
在所有的 MapReduce 框架中, Shuffle 是连接 map 任务和 reduce 任务的桥梁. map 任务的中间输出要作为 reduce 任务的输入, 就必须经过 Shuffle, 所以 Shuffle 的性能的优劣直接决定了整个计算引擎的性能和吞吐量.
相比于 Hadoop 的 MapReduce, 我们将看到 Spark 提供了多种结算结果处理的方式及对 Shuffle 过程进行的多种优化.
Shuffle 是所有 MapReduce 计算框架必须面临的执行阶段, Shuffle 用于打通 map 任务的输出与reduce 任务的输入.
通用的 MapReduce 框架: