1.2 Kylin 架构
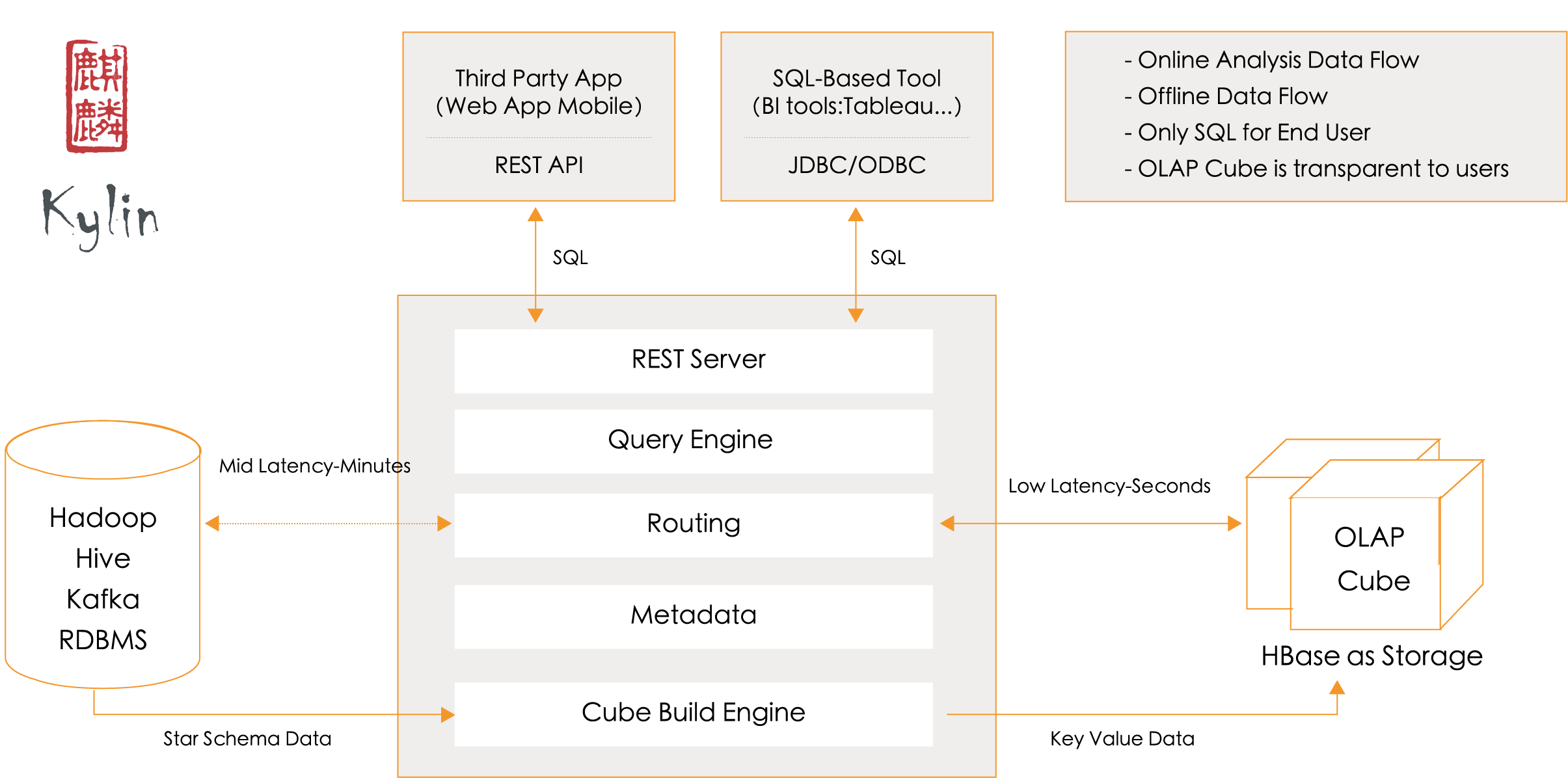
1. 数据源
我们首先来看看离线构建的部分.
从上图可以看出, 数据源在左侧, 保存着待分析的用户数据.
数据源可以是: Hadoop,
但是 Hive 是用的最多的一中数据源
2. Cube 构建引擎
Cube 构建引擎根据元数据的定义, 从数据源抽取数据, 并构建 Cube.
这套引擎的设计目的在于处理所有离线任务,其中包括 shell 脚本、Java API 以及 Map Reduce 任务等等。
任务引擎对 Kylin 当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
3. 元数据管理工具
Kylin 是一款元数据驱动型应用程序。
元数据管理工具是一大关键性组件,用于对保存在 Kylin 当中的所有元数据进行管理,其中包括最为重要的 Cube 元数据。
其它全部组件的正常运作都需以元数据管理工具为基础。
4. REST Server
此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过 Restful 接口实现 SQL 查询。
5. 查询引擎
当 Cube 准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
6. Routing(路由选择)
负责将解析的 SQL 生成的执行计划转换成 Cube 缓存的查询.
Cube 是通过预计算缓存在 Hbase 中,这部分查询可以在秒级甚至毫秒级完成
而且还有一些操作查询原始数据(存储在 Hadoop 的 hdfs 中通过 hive 查询)。这部分查询延迟较高。