9.2 从HDFS写入数据的流程
9.2.1 剖析文件的写入
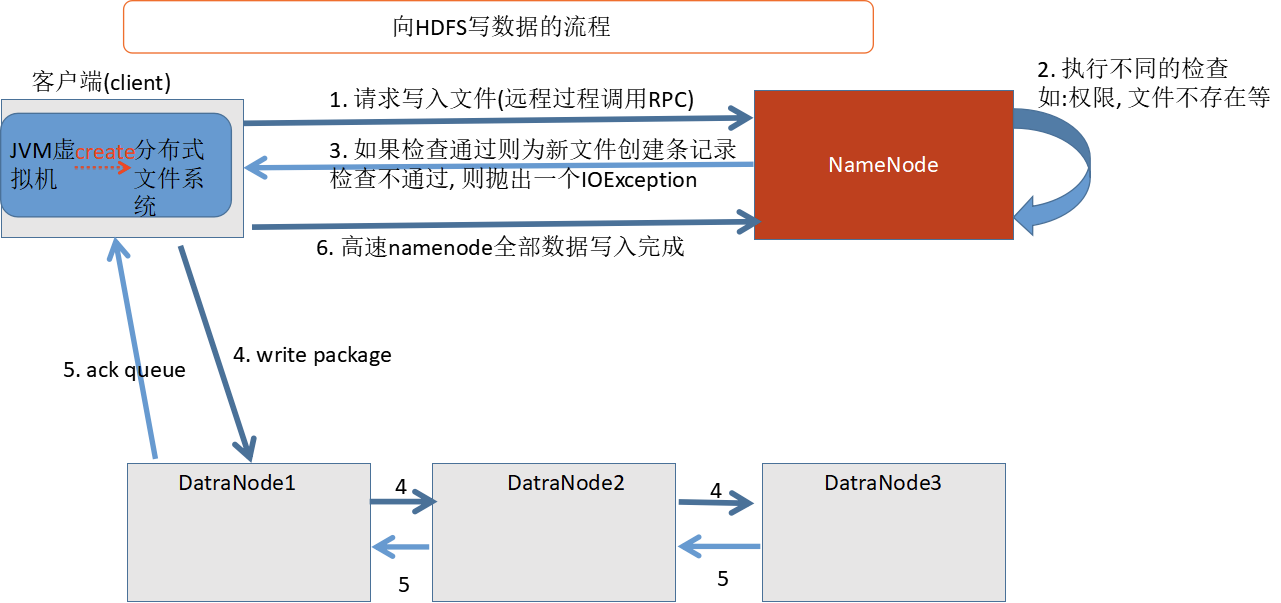
说明:
客户端通过调用
DistributedFileSystem的creat()方法, 则DistributedFileSystem会通过RPC调用namenode, 在文件的命名空间中创建一个文件, 只是这个时候文件还没有数据块而已.namenode执行各种检查, 如果通过则创建一个新文件的记录, 并返回一个FSDataOutputStream对象, 可以通过输出流对象写入数据. 如果不通过, 则会抛出一个异常:IOExceptionFSDataOutputStream负责datanode和namenode之间的通信.在客户端写入数据的时候,
FSDataOutputStream会把数据分成一个个的数据包, 并把这些写入内部的一个队列中, 我们把这个队列成为"数据队列(data queue)"FSDataOutputStream挑选出适合存储数据副本的一组datanode, 然后要求namenode去分配新的数据块.这一组
datanode构成一个管线, 假设副本数为 3 , 则管线中有 3 个节点.FSDataOutputStream把数据包存储到管线中的第 1 个节点, 第 1 个节点存储数据, 第 1 个节点并把数据发送到 2 个节点. 然后第 2 个节点再做与第 1 个节点相同的操作.FSDataOutputStream也维护着一个数据包队列来等待datanode的收到确认回执. 这个队列称为"确认队列(ack queue)". 当收到所有的datanode的确认信息后, 该数据包才会从数据队列中删除.
如果写入的过程中发生了错误, 怎么办?
如果发生错误, 首先关闭管线, 把错误信息告知namenode, 从"管线"中删除故障的datanode, 基于两个正常的datanode就构成了一条新管线. 余下的数据会继续写入到正常的datanode组成的新管线中.
当namenode发现副本不足的时候, 会在另外一个datanode上创建新的副本.
当故障的datanode恢复后, namnode会删除存储的部分数据.