6.2 Kafka Stream 数据清洗
需求
实时处理单词带有>>>前缀的内容。例如输入 atguigu>>>ximenqing,最终处理成 ximenqing
需求分析
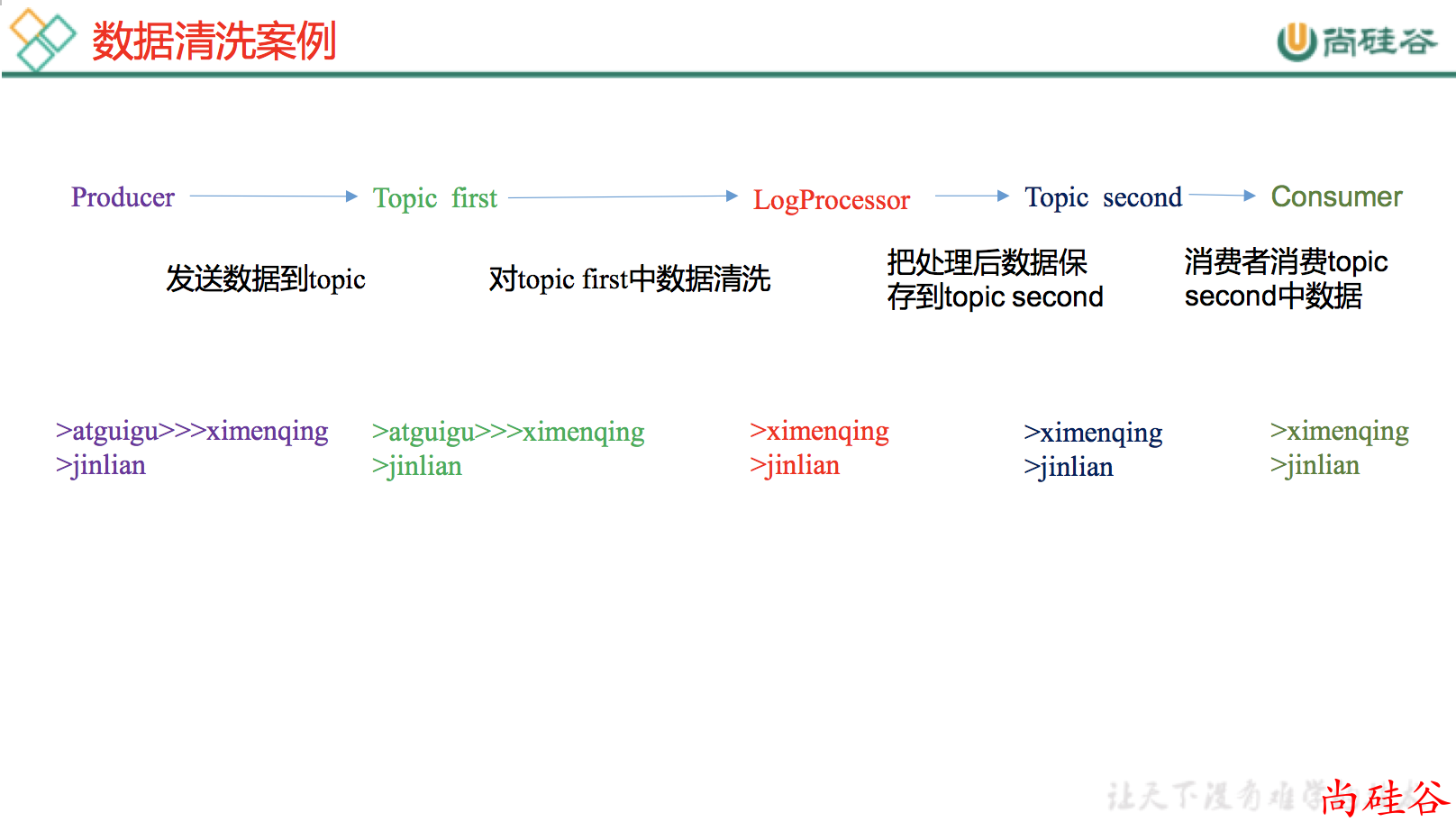
实例操作
1. 添加依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-streams -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.11.0.3</version>
</dependency>
2. 代码
主类
package com.atguigu.kafka.stream;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import org.apache.kafka.streams.processor.TopologyBuilder;
import java.util.Properties;
public class MyStream {
public static void main(String[] args) {
final String sourceTopic = "first";
final String sinkTopic = "second";
// 1. 设置参数
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "mystreams");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop201:9092");
// 2. 创建拓扑结构builder对象
TopologyBuilder builder = new TopologyBuilder()
.addSource("source", "first")
.addProcessor("processor", new MySupplier(), "source")
.addSink("sink", "second", "processor");
KafkaStreams streams = new KafkaStreams(builder, props);
// 3. 启动 kafka steams
streams.start();
}
}
具体业处理
package com.atguigu.kafka.stream;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext;
import org.apache.kafka.streams.processor.ProcessorSupplier;
public class MySupplier implements ProcessorSupplier<byte[], byte[]> {
@Override
public Processor<byte[], byte[]> get() {
return new MyProcessor();
}
private class MyProcessor implements Processor<byte[], byte[]> {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(byte[] key, byte[] value) {
byte[] newValue = new String(value).replace(">>>", "").getBytes();
context.forward(key, newValue);
}
@Override
public void punctuate(long l) {
}
@Override
public void close() {
}
}
}
3. 测试
a:运行主程序
b:开启生成者向 topic first 写入数据
kafka-console-producer.sh --broker-list hadoop201:9092 --topic first
c: 开启消费者从 topic second 消费数据
kafka-console-consumer.sh --zookeeper hadoop201:2181 --topic second
d: 开始写入数据, 并观察消费消费的数据
写入的数据:

消费到的数据:
